transformExpression
要实现的开发者接口和当前挑战
首先,看看这个组件.
<script>
import { ref } from 'chibivue'
export default {
setup() {
const count = ref(0)
const increment = () => {
count.value++
}
return { count, increment }
},
}
</script>
<template>
<div>
<button :onClick="increment">count + count is: {{ count + count }}</button>
</div>
</template>这个组件有几个问题.
由于这个组件是用 SFC 编写的,没有使用 with 语句.
换句话说,绑定没有正常工作.
让我们看看编译后的代码.
const _sfc_main = {
setup() {
const count = ref(0)
const increment = () => {
count.value++
}
return { count, increment }
},
}
function render(_ctx) {
const { h, mergeProps, normalizeProps, normalizeClass, normalizeStyle } =
ChibiVue
return h('div', null, [
'\n ',
h('button', normalizeProps({ onClick: increment }), [
'count + count is: ',
_ctx.count + count,
]),
'\n ',
])
}
export default { ..._sfc_main, render }- 问题 1:注册为事件处理器的
increment无法访问_ctx.
这是因为在之前的v-bind实现中没有添加前缀. - 问题 2:表达式
count + count无法访问_ctx.
关于 mustache 语法,它只在开头添加_ctx.,无法处理其他标识符.
因此,表达式中出现的所有标识符都需要加上_ctx.前缀.这适用于所有部分,不仅仅是 mustache.
看起来需要一个过程来为表达式中出现的标识符添加 _ctx..
期望的编译结果
const _sfc_main = {
setup() {
const count = ref(0)
const increment = () => {
count.value++
}
return { count, increment }
},
}
function render(_ctx) {
const { h, mergeProps, normalizeProps, normalizeClass, normalizeStyle } =
ChibiVue
return h('div', null, [
'\n ',
h('button', normalizeProps({ onClick: _ctx.increment }), [
'count + count is: ',
_ctx.count + _ctx.count,
]),
'\n ',
])
}
export default { ..._sfc_main, render }WARNING
实际上,原始实现采用了稍微不同的方法.
如下所示,在原始实现中,从 setup 函数绑定的任何内容都通过 $setup 解析.
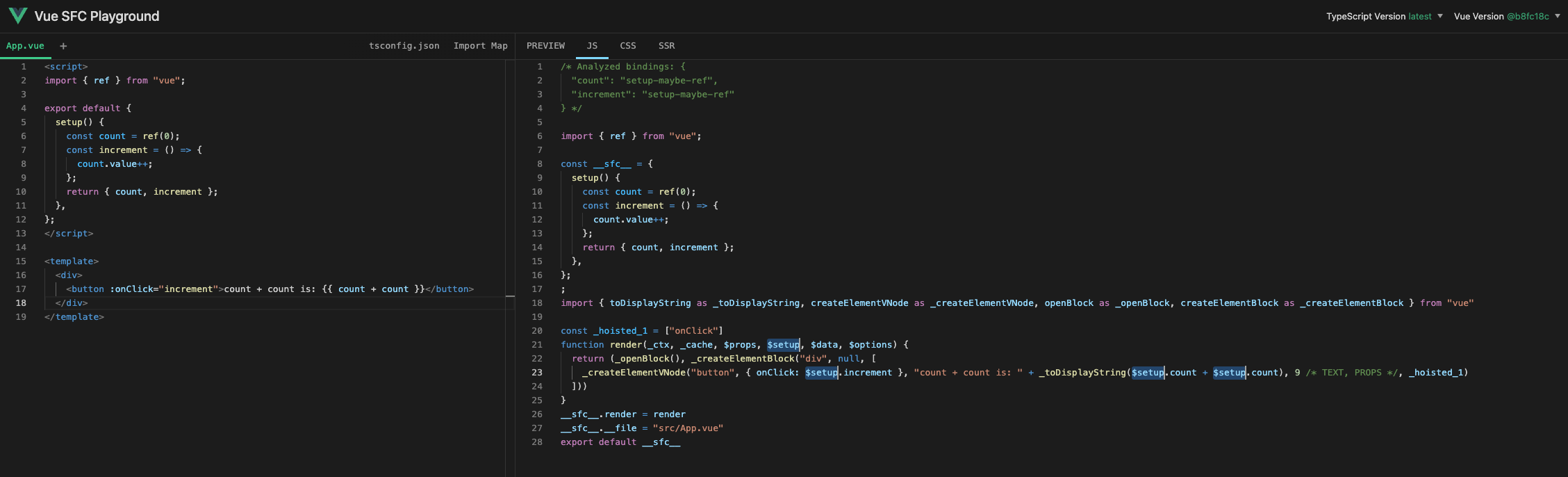
然而,实现这个有点困难,所以我们将简化它并通过添加 _ctx. 来实现.(所有 props 和 setup 都将从 _ctx 解析)
实现方法
简单来说,我们想要做的是"在 ExpressionNode 上的每个标识符(名称)的开头添加 _ctx.".
让我更详细地解释一下.
作为回顾,程序通过解析被表示为 AST.
表示程序的 AST 主要有两种类型的节点:Expression 和 Statement.
这些通常被称为表达式和语句.
1 // 这是一个 Expression
ident // 这是一个 Expression
func() // 这是一个 Expression
ident + func() // 这是一个 Expression
let a // 这是一个 Statement
if (!a) a = 1 // 这是一个 Statement
for (let i = 0; i < 10; i++) a++ // 这是一个 Statement我们这里要考虑的是 Expression.
有各种类型的表达式.Identifier 是其中之一,它是由标识符表示的表达式.
(你可以将其视为一般的变量名)
Identifier 出现在表达式的各个地方.
1 // 无
ident // ident --- (1)
func() // func --- (2)
ident + func() // ident, func --- (3)这样,Identifier 出现在表达式的各个地方.
你可以通过在以下网站输入程序来观察 ExpressionNode 上的各种 Identifier,该网站允许你观察 AST.
https://astexplorer.net/#/gist/670a1bee71dbd50bec4e6cc176614ef8/9a9ff250b18ccd9000ed253b0b6970696607b774
搜索标识符
现在我们知道了我们想要做什么,我们如何实现它?
看起来很困难,但实际上很简单.我们将使用一个名为 estree-walker 的库.
https://github.com/Rich-Harris/estree-walker
我们将使用这个库来遍历通过 babel 解析获得的 AST.
用法非常简单.只需将 AST 传递给 walk 函数,并将每个 Node 的处理描述为第二个参数.
这个 walk 函数逐个节点遍历 AST,到达该 Node 时的处理通过 enter 选项完成.
除了 enter,还有像 leave 这样的选项来在该 Node 结束时处理.我们这次只使用 enter.
创建一个名为 compiler-core/babelUtils.ts 的新文件,并实现可以对 Identifier 执行操作的实用函数.
首先,安装 estree-walker.
npm install estree-walker
npm install -D @babel/types # 也安装这个import { Identifier, Node } from '@babel/types'
import { walk } from 'estree-walker'
export function walkIdentifiers(
root: Node,
onIdentifier: (node: Identifier) => void,
) {
;(walk as any)(root, {
enter(node: Node) {
if (node.type === 'Identifier') {
onIdentifier(node)
}
},
})
}然后,为表达式生成 AST 并将其传递给此函数,在重写节点的同时执行转换.
transformExpression 的实现
InterpolationNode 的 AST 和解析器更改
我们将实现转换过程的主体 transformExpression.
首先,我们将修改 InterpolationNode,使其具有 SimpleExpressionNode 而不是字符串作为其内容.
export interface InterpolationNode extends Node {
type: NodeTypes.INTERPOLATION
content: string
content: ExpressionNode
}通过这个更改,我们还需要修改 parseInterpolation.
function parseInterpolation(
context: ParserContext,
): InterpolationNode | undefined {
// .
// .
// .
return {
type: NodeTypes.INTERPOLATION,
content: {
type: NodeTypes.SIMPLE_EXPRESSION,
isStatic: false,
content,
loc: getSelection(context, innerStart, innerEnd),
},
loc: getSelection(context, start),
}
}转换器的实现(主体)
为了使表达式转换在其他转换器中可用,我们将其提取为名为 processExpression 的函数. 在 transformExpression 中,我们将处理 INTERPOLATION 和 DIRECTIVE 的 ExpressionNode.
export const transformExpression: NodeTransform = node => {
if (node.type === NodeTypes.INTERPOLATION) {
node.content = processExpression(node.content as SimpleExpressionNode)
} else if (node.type === NodeTypes.ELEMENT) {
for (let i = 0; i < node.props.length; i++) {
const dir = node.props[i]
if (dir.type === NodeTypes.DIRECTIVE) {
const exp = dir.exp
const arg = dir.arg
if (exp && exp.type === NodeTypes.SIMPLE_EXPRESSION) {
dir.exp = processExpression(exp)
}
if (arg && arg.type === NodeTypes.SIMPLE_EXPRESSION && !arg.isStatic) {
dir.arg = processExpression(arg)
}
}
}
}
}
export function processExpression(node: SimpleExpressionNode): ExpressionNode {
// TODO:
}接下来,让我们解释 processExpression 的实现. 首先,我们将实现一个名为 rewriteIdentifier 的函数来重写 node 内的 Identifier. 如果 node 是单个 Identifier,我们简单地应用此函数并返回它.
需要注意的一点是,这个 processExpression 特定于 SFC(单文件组件)情况(不使用 with 语句的情况). 换句话说,如果设置了 isBrowser 标志,我们实现它简单地返回 node. 我们修改实现以通过 ctx 接收标志.
另外,我想保留像 true 和 false 这样的字面量,所以我将为字面量创建一个白名单.
export function processExpression(
node: SimpleExpressionNode,
ctx: TransformContext,
): ExpressionNode {
if (ctx.isBrowser) {
// 对浏览器不做任何处理
return node
}
const rawExp = node.content
const rewriteIdentifier = (raw: string) => {
return `_ctx.${raw}`
}
if (isSimpleIdentifier(rawExp)) {
node.content = rewriteIdentifier(rawExp)
return node
}
// TODO:
}makeMap 是在 vuejs/core 中实现的用于存在性检查的辅助函数,它返回一个布尔值,指示是否与用逗号分隔定义的字符串匹配.
export function makeMap(
str: string,
expectsLowerCase?: boolean,
): (key: string) => boolean {
const map: Record<string, boolean> = Object.create(null)
const list: Array<string> = str.split(',')
for (let i = 0; i < list.length; i++) {
map[list[i]] = true
}
return expectsLowerCase ? val => !!map[val.toLowerCase()] : val => !!map[val]
}问题在于下一步,即如何转换 SimpleExpressionNode(不是简单的 Identifier)并转换节点. 在以下讨论中,请注意我们将处理两个不同的 AST:Babel 生成的 JavaScript AST 和 chibivue 定义的 AST. 为了避免混淆,我们在本章中将前者称为 estree,后者称为 AST.
策略分为两个阶段.
- 在收集节点的同时替换 estree 节点
- 基于收集的节点构建 AST
首先,让我们从阶段 1 开始. 这相对简单.如果我们可以用 Babel 解析原始 SimpleExpressionNode 内容(字符串)并获得 estree,我们可以通过我们之前创建的实用函数传递它并应用 rewriteIdentifier. 此时,我们收集 estree 节点.
import { parse } from '@babel/parser'
import { Identifier } from '@babel/types'
import { walkIdentifiers } from '../babelUtils'
interface PrefixMeta {
start: number
end: number
}
export function processExpression(
node: SimpleExpressionNode,
ctx: TransformContext,
): ExpressionNode {
// .
// .
// .
const ast = parse(`(${rawExp})`).program // ※ 这个 ast 指的是 estree。
type QualifiedId = Identifier & PrefixMeta
const ids: QualifiedId[] = []
walkIdentifiers(ast, node => {
node.name = rewriteIdentifier(node.name)
ids.push(node as QualifiedId)
})
// TODO:
}需要注意的一点是,到目前为止,我们只操作了 estree,没有操作 ast 节点.
CompoundExpression
接下来,让我们进入阶段 2.在这里,我们将定义一个名为 CompoundExpressionNode 的新 AST Node. Compound 意味着"组合"或"复杂性".这个 Node 有 children,它们采用稍微特殊的值. 首先,让我们看看 AST 的定义.
export interface CompoundExpressionNode extends Node {
type: NodeTypes.COMPOUND_EXPRESSION
children: (
| SimpleExpressionNode
| CompoundExpressionNode
| InterpolationNode
| TextNode
| string
)[]
}Children 采用如上所示的数组. 要理解这个 Node 中的 children 代表什么,看具体例子会更容易,所以让我们给出一些例子.
以下表达式将被解析为以下 CompoundExpressionNode:
count * 2{
"type": 7,
"children": [
{
"type": 4,
"isStatic": false,
"content": "_ctx.count"
},
" * 2"
]
}这是一种相当奇怪的感觉."children" 采用字符串类型的原因是因为它采用这种形式. 在 CompoundExpression 中,Vue 编译器将其分为必要的粒度,并部分表示为字符串或部分表示为 Node. 具体来说,在像这样重写 Expression 中存在的 Identifier 的情况下,只有 Identifier 部分被分为另一个 SimpleExpressionNode.
换句话说,我们要做的是基于收集的 estree 的 Identifier Node 和源生成这个 CompoundExpression. 以下代码是为此的实现.
export function processExpression(node: SimpleExpressionNode): ExpressionNode {
// .
// .
// .
const children: CompoundExpressionNode['children'] = []
ids.sort((a, b) => a.start - b.start)
ids.forEach((id, i) => {
const start = id.start - 1
const end = id.end - 1
const last = ids[i - 1]
const leadingText = rawExp.slice(last ? last.end - 1 : 0, start)
if (leadingText.length) {
children.push(leadingText)
}
const source = rawExp.slice(start, end)
children.push(
createSimpleExpression(id.name, false, {
source,
start: advancePositionWithClone(node.loc.start, source, start),
end: advancePositionWithClone(node.loc.start, source, end),
}),
)
if (i === ids.length - 1 && end < rawExp.length) {
children.push(rawExp.slice(end))
}
})
let ret
if (children.length) {
ret = createCompoundExpression(children, node.loc)
} else {
ret = node
}
return ret
}Babel 解析的 Node 有 start 和 end(它对应于原始字符串的位置信息),所以我们基于此从 rawExp 中提取相应的部分并仔细分割. 请仔细查看源代码了解更多详细信息.如果你理解到目前为止的策略,你应该能够阅读它.(另外,请查看 advancePositionWithClone 等的实现,因为它们是新实现的.)
现在我们可以生成 CompoundExpressionNode,让我们也在 Codegen 中支持它.
function genInterpolation(
node: InterpolationNode,
context: CodegenContext,
option: Required<CompilerOptions>,
) {
genNode(node.content, context, option)
}
function genCompoundExpression(
node: CompoundExpressionNode,
context: CodegenContext,
option: Required<CompilerOptions>,
) {
for (let i = 0; i < node.children!.length; i++) {
const child = node.children![i]
if (isString(child)) {
// 如果是字符串,按原样推送
context.push(child)
} else {
// 对于其他任何内容,为 Node 生成 codegen
genNode(child, context, option)
}
}
}(genInterpolation 已经变成了只是 genNode,但我现在将保留它.)
试试看
现在我们已经实现到这里,让我们完成编译器并尝试运行它!
// 添加 transformExpression
export function getBaseTransformPreset(): TransformPreset {
return [[transformElement], { bind: transformBind }]
return [[transformExpression, transformElement], { bind: transformBind }]
}import { createApp, defineComponent, ref } from 'chibivue'
const App = defineComponent({
setup() {
const count = ref(3)
const getMsg = (count: number) => `Count: ${count}`
return { count, getMsg }
},
template: `
<div class="container">
<p> {{ 'Message is "' + getMsg(count) + '"'}} </p>
</div>
`,
})
const app = createApp(App)
app.mount('#app')到此为止的源代码:GitHub